Hvad er deep learning, og hvordan kan det bruges i praksis?
Hvad dækker deep learning og supervised maskinlæring egentlig over? Hvordan trænes neurale netværk/algoritmer inden for maskinlæring? Hvilke overvejelser bør virksomheder gøre sig om sine tekniske kompetencer, inden de anvender maskinlæring i dataprojekter? Det svarer Globeteams konsulent Nick Rishøj Danmand på i denne faglige artikel. Nick har stor erfaring inden for udvikling og implementering af løsninger med kunstig intelligens (artificial intelligence) og underviser på Aarhus Universitet i maskinlæring.
Kunstig intelligens”, ”maskinlæring” og ”avanceret dataanalyse” er med god grund nogle af de mest omtalte begreber. I Danmark ser vi ofte en bred tilgang til termerne, og de bruges flittigt i forlængelse af hinanden. Og de er da også langt hen ad vejen relateret. Lad os starte med kort at se nærmere på definitionen af kunstig intelligens (artificial intelligence), inden vi dykker ned i supervised maskinlæring og eksempler på de kompetencemæssige overvejelser, man bør gøre sig, før man som virksomhed anvender maskinlæring.
Kunstig intelligens er efterhånden alment kendt og bruges ofte, når nye visioner og strategier skal formuleres, eller projekter skal sælges. I virkeligheden er kunstig intelligens en meget bred formulering for systemer, som demonstrerer en form for menneskelignende intelligens indenfor planlægning, læring, ræsonnement og problemløsning. Mens kunstig intelligens er den brede videnskab om at efterligne menneskelige evner, er maskinlæring et underområde indenfor kunstig intelligens.
Maskinlæring er læren ved hjælp af erfaring (data) og er metoder til træning af algoritmer, så maskinen – på baggrund af algoritme og data – kan træffe beslutninger. Et eksempel herpå kunne være at spotte fejl ved et produkt ved at analysere et billede af produktet.
Supervised maskinlæring – Deep learning
Maskinlæring kan overordnet opdeles i flere hovedkategorier. To ofte omtalte kategorier er supervised maskinlæring og unsupervised maskinlæring.
I en supervised maskinlæringsmodel lærer algoritmen på et ”mærket” datasæt, hvilket giver en responsnøgle, som algoritmen kan bruge til at evaluere dens nøjagtighed på de data, modellen baseres på; såkaldte træningsdata. Supervised maskinlæring foretages ofte med udgangspunkt i klassifikations- eller regressionsproblemer, hvor målet er at kategorisere eller estimere en given værdi ud fra de givne data.
En maskinlæringsteknik, som ofte anvendes til supervised maskinlæring, er kunstige neurale netværk (artificial neural networks). Disse algoritmer falder indenfor en samlet kategori af algoritmer, som kaldes deep learning. Deep learning, og teorien bag det kunstige neurale netværk, har eksisteret siden 1950, men har først fundet egentlig anvendelse siden år 2000. Forskning i deep learning har sidenhen taget fart, bl.a. grundet nutidens computerkraft, og i dag anvendes deep learning i alt fra simple regressionsproblemer til komplekse styringssystemer, såsom autonome biler og stemmekontrollerede enheder (f.eks. Apple Siri eller Amazon Alexa).
Kunstige neurale netværk består – i hovedreglen – af et inputlag, en række mellemliggende (skjulte) lag og et output-/slutlag. Når algoritmerne trænes, siges det, at netværket ”lærer” på baggrund af de træningsdata, som modellen fodres med. Slutteligt vil modellen – hvis trænet korrekt – være i stand til at forudsige (predicte) nye værdier ud fra ukendt data. F.eks. er Apple Siri i stand til at forstå, hvad iPhone-brugere siger til telefonen. Dette skyldes ikke, at Siri at trænet til at forstå den enkelte bruger, men nærmere at Siri blev trænet på forhånd til at forstå alle iPhone-brugere.
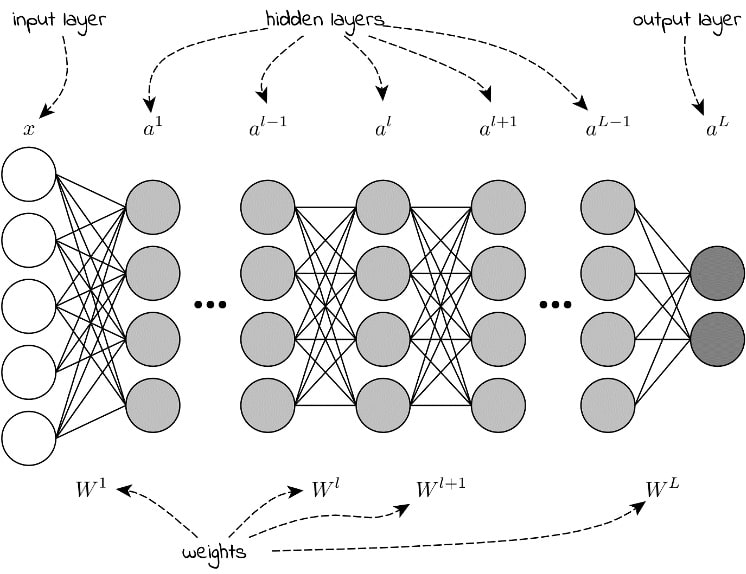
Som illustrationen viser, er der forbindelser imellem hvert lag i et neuralt netværk. Disse forbindelser kaldes vægte (forbindelser), og det er netop disse, som justeres under træning af en model. Når man påbegynder træning af en model, vil man typisk give alle vægte en vilkårlig værdi, f.eks. mellem 0 og 1. Idet data fodres til netværket, aktiveres forbindelserne mellem to noder i to lag. Helt konkret har ethvert lag en tilknyttet activation function, som kombinerer input-data med den angivne vægt, som er knyttet til forbindelsen mellem noderne. På tværs af et dybt neuralt netværk vil der ofte være millioner af forbindelser, som alle påvirker slutresultatet (output) af netværket. Det er netop disse beregninger, som giver vores endelige resultat.
I forsimplet forstand kan man altså betragte resultatet som en funktion af netværkets input og de vægte, som befinder sig mellem alle noderne. Vægtene tilpasses ved træning af netværket. Ved hjælp af nogle simple matematiske regler er vi i stand til at indikere, hvordan vi kan tilpasse den enkelte vægt med henblik på at gøre modellen i stand til at forudsige det rigtige resultatet.
Produktionsvirksomheds anvendelse af deep learning til fejlsøgning
Vi kan altså ved hjælp af eksisterende data udvikle neurale netværk, som kan assistere en række processer. Som eksempel herpå tager vi udgangspunkt i en typisk produktionsvirksomhed.
Virksomheden producerer en række produkter, som til slut sendes ud til kunder. Hvis et produkt er fejlbehæftet, vil kunden returnere det til virksomheden. En ofte bekostelig affære. Derfor ønsker virksomheden at spotte eventuelle fejl, allerede inden produkterne sendes ud til kunder.
Virksomheden er i stand til at udnytte det eksisterende datagrundlag til at træne en model baseret på neurale netværk – en model som er i stand til at spotte fejl på produkterne. Helt konkret kan disse data eksempelvis være vægt, mål, farver, billeder m.m., som alle er med til at beskrive et produkt. Ved at lære modellen om produkter, som er fejlbehæftede, er modellen i stand til at spotte fejl på nye produkter, som menneskets øje nemmere overser.
Ofte bliver deep learning også anvendt til afløftning af fakturadata. Flere regnskabssystemer anvender i dag OCR til at digitalisere dokumenter. Avancerede modeller baseret på deep learning gør det muligt at aflæse og digitalisere dokumenter med hidtil uset nøjagtighed. Læs case “Fondsvirksomhed vil højne kvaliteten af deres regnskabsprocesser med AI”
Deep learning og kunstige neurale netværk er blot én af mange algoritmer indenfor supervised maskinlæring. Se vores øvrige artikler og e-bøger om maskinlæring og AI.
Kompetencemæssige overvejelser før anvendelse af maskinlæring
1. Ved vi, hvordan algoritmer parres med de rigtige værktøjer og processer?
Vi er interesserede i at finde de bedste algoritmer til de rette processer for at maksimere værdien ved maskinlæring.
2. Kan vi kombinere statistiske værktøjer og dataminingmetoder med (eksisterende) infrastruktur?
Maskinlæringmodeller kan være beregningsmæssigt tunge at træne og kræver derfor ofte dedikeret hardware.
3. Kan vi kontinuerligt måle på og optimere idriftsatte modeller?
For at sikre kvaliteten bag igangværende maskinlæringsbaserede læsninger er det nødvendigt at måle på, overvåge og gentræne løsningen.


